초록
문서 레이아웃 분석(Document Layout Analysis)은 실제 문서 이해 시스템에서 매우 중요하지만, 속도와 정확성 간의 어려운 균형을 맞추어야 하는 과제가 있습니다. 텍스트와 시각적 특징을 모두 활용하는 멀티모달(multimodal) 방식은 높은 정확성을 달성할 수 있지만 상당한 지연 시간이 발생하는 반면, 시각적 특징만 사용하는 단일 모달(unimodal) 방식은 빠른 처리 속도를 제공하지만 정확성이 떨어집니다. 이 문제를 해결하기 위해, 우리는 사전 학습과 모델 설계에서 문서 특화 최적화를 통해 정확성을 높이면서 속도 우위를 유지하는 새로운 접근 방식인 DocLayout-YOLO를 제안합니다. 강력한 문서 사전 학습을 위해, 우리는 문서 합성을 2차원 빈 패킹 문제로 정의하는 Mesh-candidate BestFit 알고리즘을 도입하여 대규모의 다양한 DocSynth-300K 데이터셋을 생성합니다. 결과적으로 만들어진 DocSynth-300K 데이터셋으로 사전 학습하면 다양한 문서 유형에서 미세 조정 성능이 크게 향상됩니다. 모델 최적화 측면에서는 문서 요소의 다양한 규모 변화를 더 잘 처리할 수 있는 Global-to-Local Controllable Receptive Module을 제안합니다. 또한, 서로 다른 문서 유형에서 성능을 검증하기 위해 DocStructBench라는 복잡하고 도전적인 벤치마크를 도입했습니다. 다운스트림 데이터셋에 대한 광범위한 실험 결과, DocLayout-YOLO가 속도와 정확성 모두에서 뛰어난 성과를 보여주었습니다.
서론
DocLayout-YOLO는 문서 레이아웃 분석(DLA)에서 속도와 정확성의 균형을 맞추기 위해 설계된 모델입니다. 기존 DLA 방식은 시각적 정보만 사용하는 단일 모달(unimodal) 방식과 텍스트 및 시각 정보를 모두 사용하는 멀티모달(multimodal) 방식으로 나뉩니다. 이 모델은 새로운 학습 데이터셋 DocSynth-300K와 메쉬-후보 적합 알고리즘(Mesh-candidate BestFit)을 이용하여 다양한 문서 형식에 대한 분석 정확성을 높이고, 모델 구조의 최적화를 통해 속도도 개선했습니다.
관련 연구
기존의 DLA 방식 및 사용된 데이터셋의 한계를 설명합니다. 예를 들어, LayoutLMv3와 같은 멀티모달 모델은 큰 규모의 데이터로 학습해 일반화 성능이 뛰어나지만, 속도가 느린 문제가 있습니다. 단일 모달 방식은 상대적으로 속도는 빠르지만 정확성이 떨어지는 문제가 있습니다.
DocSynth-300K 데이터셋 구성
이 항목에서는 DocSynth-300K라는 새로운 데이터셋을 구축하는 과정이 설명됩니다. 문서 요소(예: 텍스트, 이미지, 표)의 다양성과 레이아웃의 다양성을 고려하여 메쉬-후보 적합 알고리즘을 사용해 현실에 가까운 문서 레이아웃을 자동으로 생성합니다. 이를 통해 다양한 문서에 대해 더 나은 모델 학습이 가능하게 합니다.
글로벌-로컬 모델 아키텍처(Global-to-Local Model Architecture)
DocLayout-YOLO의 모델 구조는 다양한 크기의 문서 요소를 효과적으로 감지하기 위해 GL-CRM(Global-to-Local Controllable Receptive Module)을 포함합니다. 이 모듈은 전역에서 지역으로 정보가 흐르도록 설계되어, 문서 전반의 큰 요소부터 작은 지역 요소까지 다양한 규모의 특징을 감지합니다.
실험 및 성능 평가
DocLayout-YOLO의 성능을 평가하기 위해 다양한 실험이 진행되었습니다. DocLayout-YOLO는 기존 모델에 비해 속도와 정확성에서 우수한 성과를 보였으며, 특히 DocStructBench라는 복잡한 문서 평가 데이터셋에서 뛰어난 성능을 나타냈습니다.
비교 및 분석
DocLayout-YOLO는 기존의 다양한 DLA 방식과 비교한 결과, 대부분의 경우 더 높은 정확성과 속도를 기록했습니다. 또한, 여러 문서 형식에서 기존의 데이터셋과 비교해 DocSynth-300K가 더 뛰어난 일반화 성능을 보였습니다.
추가 실험 및 데이터셋 비교
데이터셋의 크기와 구성이 모델 성능에 미치는 영향을 조사한 실험 결과, DocSynth-300K는 다른 생성 방법이나 공공 데이터셋에 비해 더 나은 성능 향상을 보여줬습니다.
결론
이 논문에서는 속도와 정확성에서 뛰어난 DocLayout-YOLO를 제안합니다. DocLayout-YOLO는 사전 학습과 모델 최적화 측면에서 개선된 기술을 포함하고 있습니다. 사전 학습을 위해서는 고품질의 다양한 DLA(DocLayout Analysis) 사전 학습 데이터셋인 DocSynth-300K를 합성하는 Mesh-candidate BestFit 방법론을 제안하고, 모델 최적화 측면에서는 계층적 글로벌-블록-로컬 방식으로 문서 이미지를 인식하는 GL-CRM(Global-to-Local Controllable Receptive Module)을 도입했습니다. 광범위한 다운스트림 데이터셋에 대한 실험 결과, DocLayout-YOLO는 기존의 DLA 방법들에 비해 속도와 정확성 모두에서 현저히 우수한 성능을 보여줍니다.
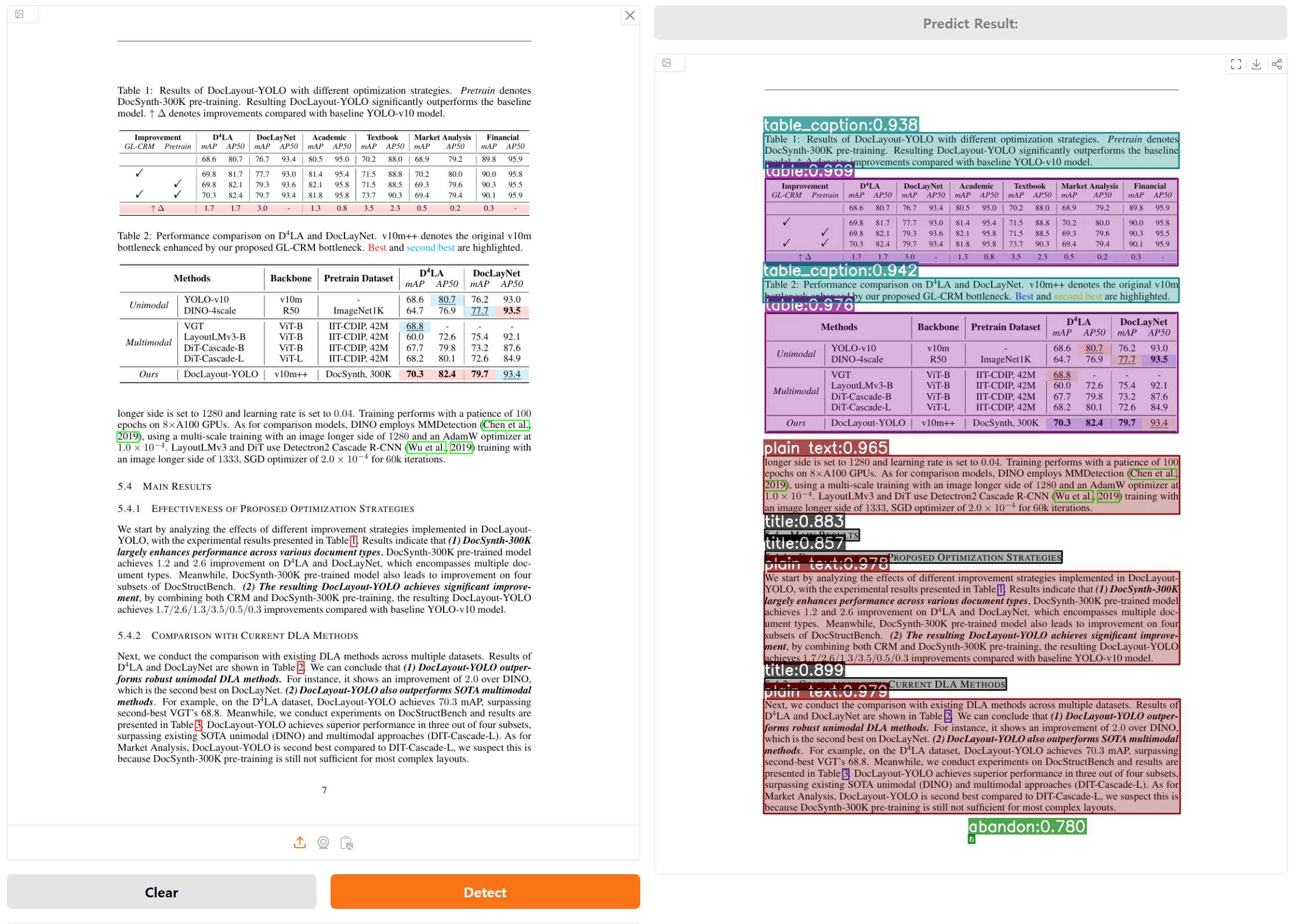
아래 이미지는 DocLayout YOLO demo 페이지에서 확인한 결과입니다.

DocLayout-YOLO: Enhancing Document Layout Analysis through Diverse Synthetic Data and Global-to-Local Adaptive Perception
Document Layout Analysis is crucial for real-world document understanding systems, but it encounters a challenging trade-off between speed and accuracy: multimodal methods leveraging both text and visual features achieve higher accuracy but suffer from sig
arxiv.org
DocLayout YOLO - a Hugging Face Space by opendatalab
DocLayout YOLO - a Hugging Face Space by opendatalab
Running on Zero
huggingface.co
GitHub - opendatalab/DocLayout-YOLO: DocLayout-YOLO: Enhancing Document Layout Analysis through Diverse Synthetic Data and Globa
DocLayout-YOLO: Enhancing Document Layout Analysis through Diverse Synthetic Data and Global-to-Local Adaptive Perception - opendatalab/DocLayout-YOLO
github.com
'AI > LLM' 카테고리의 다른 글
| WoT(Whiteboard-of-Thought) 대형 언어 모델의 한계를 넘다. 시각적 사고 구현하기. (4) | 2024.11.06 |
|---|---|
| OpenAI API의 Structured Outputs: 기능 호출과 JSON 스키마 활용법 (3) | 2024.10.23 |
| Grok-2 Beta 블로그 내용 정리(xAI) (5) | 2024.09.02 |
| AI 엔지니어와 데이터 과학자를 위한 Phoenix (1) | 2024.08.29 |
| AI로 미래의 과학을 여는 길: 독립적인 연구와 논문 작성이 가능한 'The AI Scientist'(sakana ai) (7) | 2024.08.26 |



